

本文作家团队来自阿里巴巴集团,共同第一作家为深度学习参谋员刘锦龙和何旺贵,通信作家为姜浩。
用强化学习(RL)优化文生图模子的 prompt following 才调,是一条被粗鄙考据的旅途 —— 让模子把柄 prompt 用不同赶紧种子生成多张图片,通过 reward model 打算 reward,再应用干系 RL 算法优化模子。
这内部最中枢的问题在于:reward 信号从哪来?
传统的对都规划如 CLIP Score 粒渡过粗,无法捕捉属性绑定、空间关系、计数等复杂语义。现时一些开源的 reward 模子(PickScore、ImageReward、HPS v2 等)受限于模子界限和有限的标注数据,难觉得最前沿的工业级的文生图模子提供有用反馈信号。而磨真金不怕火一个高质料的 reward 模子时时代价不低 —— 需要花消无数东说念主力和资本进行标注和磨真金不怕火。
另一方面,开源社区的多模态大模子(VLM)执续发展,这些模子在预磨真金不怕火中见过海量图文数据,自身就具备丰富的图文对都学问,是自然的图文一致性 reward 信号开头。问题在于:怎样把这些学问从 VLM 中高效地索要出来动作 reward?
为此,来自阿里巴巴的参谋团队建议了 PromptEcho—— 一种无需任何标注、无需磨真金不怕火 reward 模子,仅通过冻结 VLM 的一次前向推理就能获取高质料 reward 的尺度。

论文:https://arxiv.org/abs/2604.12652
开源代码 & 模子权重:https://github.com/roooobotx/prompt_echo
中枢尺度:「PromptEcho」
一个直观:如若丹青对了,VLM 就能「复述」出 prompt
念念象一下:你把柄 prompt 画了一幅画,然后把画给一位一又友看,然后问他「请描摹这幅画」。如若画面诚笃地形色了「一只红色的猫站在蓝色的桌子上」,他八成率能准确复述出这些内容。VLM 亦然一样 —— 如若生成图像诚笃校服了 prompt,VLM 在看到图像后就能以很高的概率(似然)逐 token 复述出原始 prompt。或者说把 prompt 的内容「回响」(Echo)了回来,而这个复述的对数似然即是咱们要找的 reward。
反过来,如若画面中猫的神志搞错了,或者桌子不见了,VLM 复述出原始 prompt 的概率就会权贵下跌,reward 随之镌汰。
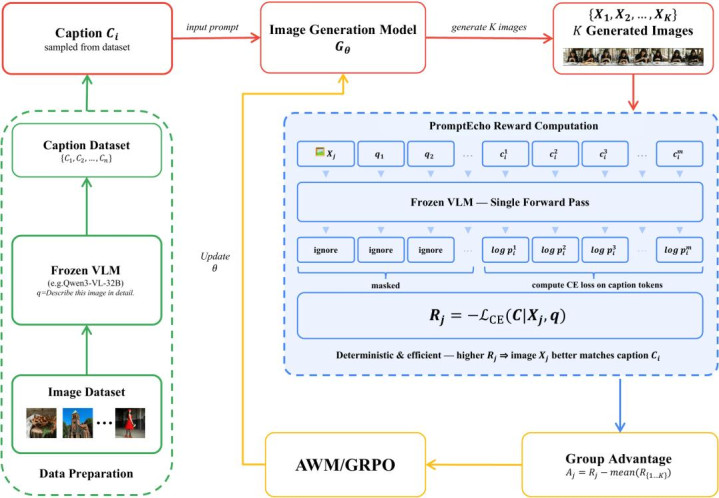
图 1:PromptEcho 经过。给定生成图像和指导 query,冻结 VLM 在 teacher-forcing 款式下打算原始 prompt 的 token 级交叉熵亏空,取负值动作 reward。
具体而言,PromptEcho 有三个输入:

然后,将图像和 query 输入冻结的 VLM,在 teacher-forcing 款式下(即不让模子解放生成,而是强制输入 prompt 的每个 token),打算 VLM 对原始 prompt 中每个 token 的预测概率。最终的 reward 即是:
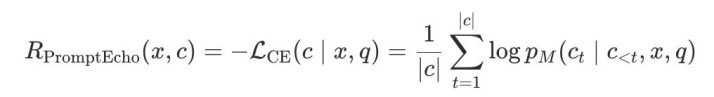
一句话总结:reward = VLM 看到图像后,能多八成率「复述」出原始 prompt。
这个 reward 与 VLM 预磨真金不怕火的亏空函数十足一致,仅仅优化对象从 VLM 的模子权重酿成了文生图模子生成的图片。这种一致性恰是 PromptEcho 高效的原因,它复用了 VLM 在预磨真金不怕火中习得的图文对都学问。
为什么不径直让 VLM 打分?
一个当然的问题是:既然用的是冻结 VLM,为什么不径直输入 prompt 和图片让 VLM 推理图文一致性评分作念 reward?为了回话这个问题,参谋团队瞎想了一个对比尺度「InferScore」—— 使用合并个冻结 VLM,但让它以自追念式样生成对图文一致性的评分,动作 reward 信号。两者的区别在于:
InferScore:让 VLM 自追念生成龙套评分 → 受幻觉和采样赶紧性影响,reward 信号不褂讪;更要害的是,开云sports受限于龙套打分机制,关于现时起先进的文生图模子,VLM 频繁无法辞别合并 prompt 下不同种子生成的多张图片在 prompt following 进度上的眇小相反 —— 好多时期对系数图片都给出相易分数,导致 reward 信号确切失效
PromptEcho:通过预磨真金不怕火亏空函数打算通顺的对数似然值 → 笃定性、无采样噪声,自然具备细粒度辞别才调
后续执行将径直考据这少许 —— 雷同基于 Qwen3-VL-32B,PromptEcho 全面优于 InferScore。
执行
PromptEcho 在两个现时最前沿的开源文生图模子(Z-Image 和 QwenImage-2512)上进行了执行,使用 Qwen3-VL-32B 动作 reward VLM。
磨真金不怕火数据构建。 参谋团队汇聚了约 10 万张高质料图片,使用 Qwen3-VL-32B 合作请示 "Describe this image in detail" 为每张图片生成约 200–400 词的详备描摹(dense caption),涵盖对象、属性、空间关系、神志、纹理等多维信息。这些 caption 组成了 RL 磨真金不怕火的 prompt 聚拢。
DenseAlignBench :密集描摹场景下对前沿模子的大幅修订
参谋团队从同源数据中划出 2000 条不在磨真金不怕火连合的 caption,构建了 DenseAlignBench 测试集。该测试集与磨真金不怕火数据同源同踱步,用于径直考据 PromptEcho 的有用性。使用 Gemini-3-flash-preview 进行成对请示校服维度的 GSB 评估:
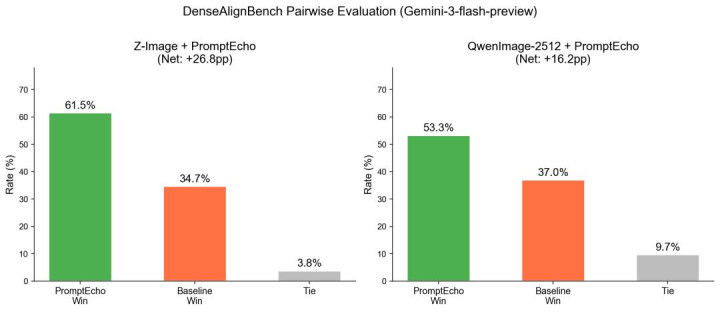
在密集描摹的场景下,PromptEcho 取得了对前沿模子的大幅修订。
公开 Benchmark:请示校服才调进步的泛化测试
需要强调的是,以下公开 benchmark 的测试 prompt 与磨真金不怕火数据在踱步上存在权贵相反 PromptEcho 莫得针对任何 benchmark 作念针对性磨真金不怕火,以下限度十足反馈请示校服才调的泛化进步:
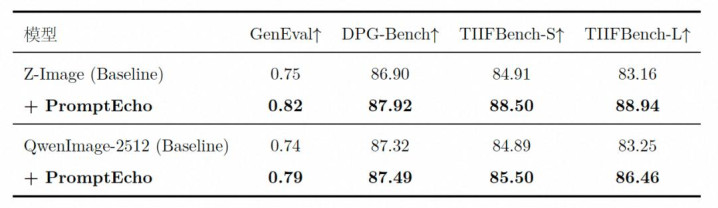
PromptEcho 在系数公开 benchmark 上均取得了一致的进步,体现了其 reward 信号源自 VLM 海量预磨真金不怕火数据中的图文对都学问,具备跨踱步、跨架构的泛化才调。
Reward VLM 越大越好:Scaling 有用
为了考据 VLM 模子自身的质料对 PromptEcho 遵循的影响,参谋团队在 Z-Image 上分别使用 Qwen3-VL-32B 和 Qwen3-VL-8B 动作 reward VLM 进行了对比执行:
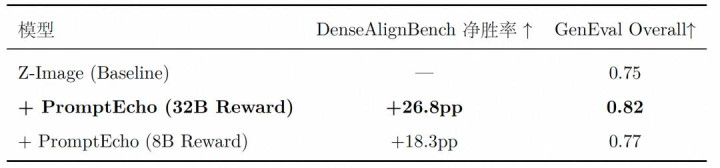
32B 在所策动键规划上向上 8B,标明 reward 质料随 VLM 界限增长。这意味着跟着开源 VLM 执续进化,PromptEcho 的遵循上限也会欺压提高。
PromptEcho vs InferScore
雷同使用 Qwen3-VL-32B,PromptEcho 和 InferScore 的对比:
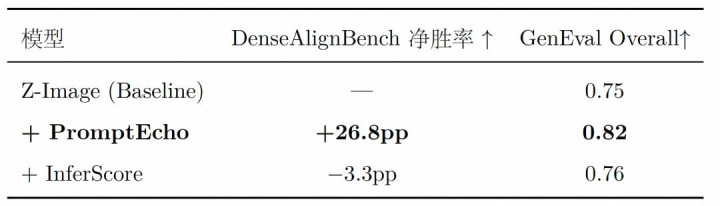
InferScore 在 DenseAlignBench 上致使不如 baseline。这个考据了前边的论断:通过预磨真金不怕火亏空函数打算通顺对数似然值,远比让 VLM 自追念生成龙套评分更可靠。
笔墨渲染:通用性考据
PromptEcho 动作通用 Reward 范式
PromptEcho 的核神思制(VLM 交叉熵 reward)并不局限于文生图模子的请示校服优化。为了考据其通用性,参谋团队将其迁徙到了一个截然有异的任务:电商海报笔墨渲染。
迁徙过程中,PromptEcho 的中枢打算十足不变,仅需适配两个输入:
指导 query:从通用描摹(「Describe this image in detail」)改为结构化 OCR 识别 prompt—— 条目 VLM 识别图中系数瞎想 / 营销笔墨,并按语义变装分类为主标题、副标题、卖点案牍、其他笔墨
经过 PromptEcho 强化学习之后,在 5000 条测试样本上,海报生成模子全图笔墨正确率从 68% 进步到 75%(+7pp)。这施展 PromptEcho 是一种通用的 reward 构建范式 —— 只需更始指导 query 和标签局势,合并套机制就能适配不同的图像生成模子和优化方向,无需为每个新任务再行磨真金不怕火专用 reward 模子。
Case 展示
下图展示了一些本色的 case: QwenImage-2512(Baseline)与经过 PromptEcho 磨真金不怕火后的模子在合并 prompt 下的生成对比。QwenImage-2512 动作现时起先进的开源文生图模子,举座请示校服才调依然可以。可以看到,经过 PromptEcho 磨真金不怕火后,模子在画面细节、空间关系、对象计数等方面有了进一步的权贵修订。

图 2:QwenImage-2512 Baseline vs PromptEcho 生成限度对比。
总结与谈判
PromptEcho 揭示了一个神圣而久了的知悉:VLM 的预磨真金不怕火亏空函数自身即是一个高质料的文图对都 reward 信号。 不需要标注数据,不需要磨真金不怕火 reward 模子,径直应用开源 VLM 的一次前向推理,就能提供高质料的请示校服 reward 信号。
这开发了一条全新的 reward 构建旅途 —— 异日跟着开源社区 VLM 执续修订,PromptEcho 将获取更高质料的 reward 信号,带来更好的优化遵循。
为了通俗社区的进一步参谋,参谋团队已开源代码、模子权重和 DenseAlignBench 测试集kaiyun sports,详见:https://github.com/roooobotx/prompt_echo。
米兰app官方网站




